



Although we are quite familiar with join operations in spark, but do you know spark has some inbuilt tricks to do joins in an efficient manner without letting you know, unless you tame spark and make it do the way you want.
PREREQUISITE:
TERMINOLOGY:
CONFIGURTION CONTROLS:
TYPES OF JOIN STRATEGIES:
Broadcast Hash Join (BHJ)
Shuffle Hash Join (SHJ)
Shuffle - Sort - Merge Join (SSMJ)
Cartesian Join (CPJ)
Broadcast Nested Loop Join (BNLJ)
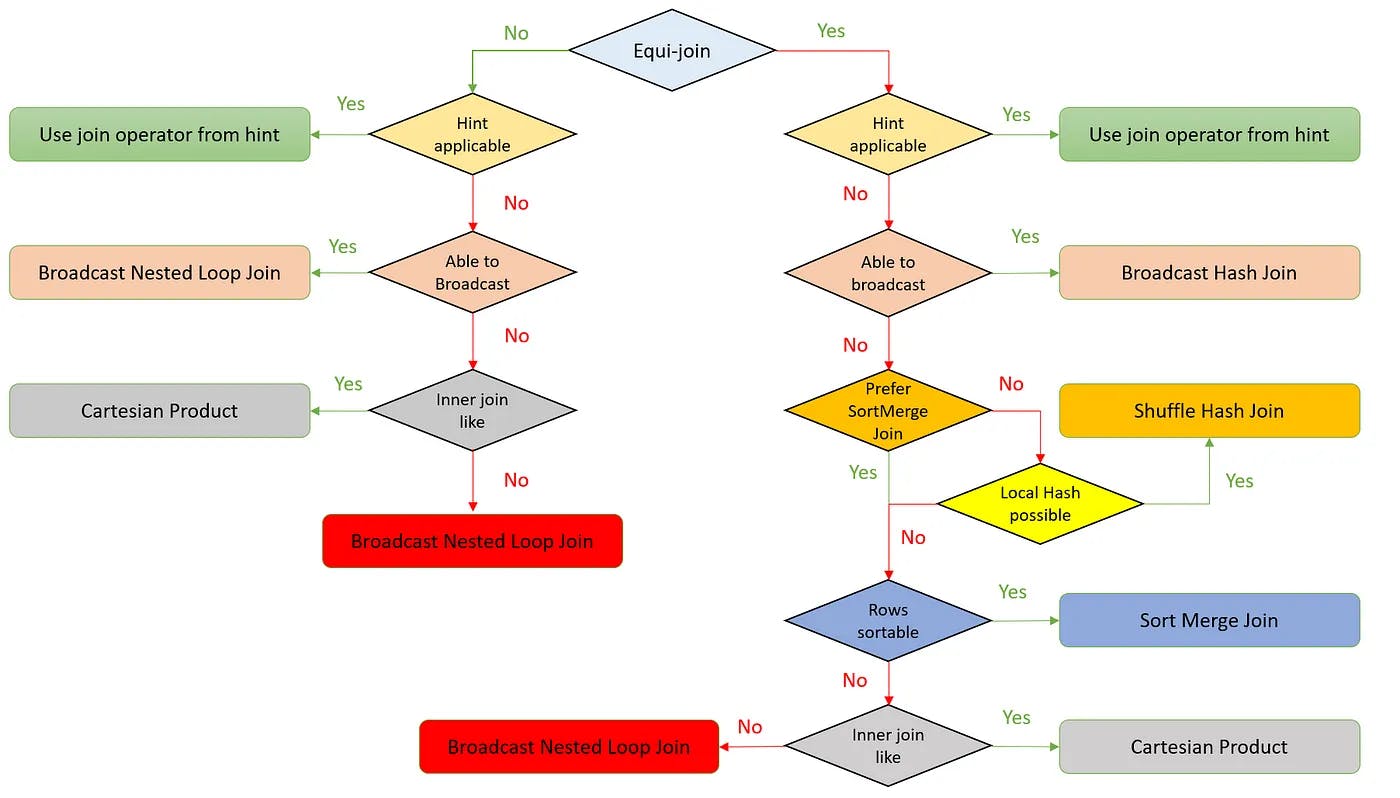
Below is chart that shows the join strategy selection process:
Broadcast Hash Join (BHJ)
As name suggest this join works in 2 phases, Broadcast & Hash.
Broadcast Phase: The smaller dataset is broadcasted to each executor that has bigger dataset partition.
Hash Phase: The smaller table is then hashed on each executor. Now join will be performed using this hashed table.
Working:
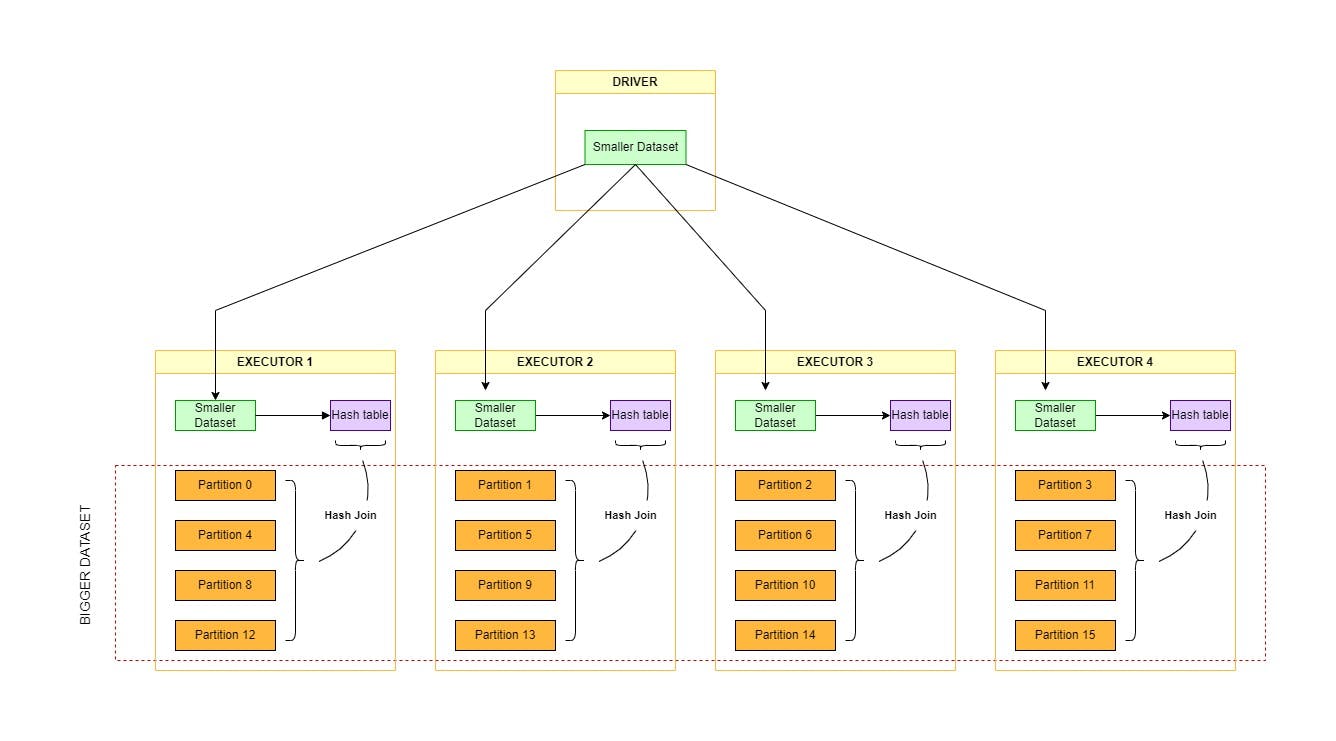
Imagine you have two tables to join, like Customers and Orders. Here's how Broadcast Hash Join (BHJ) works in Spark:
1. Identify the smaller table: BHJ works best for small datasets. Spark automatically determines which is smaller.
2. Broadcasting the small table: The smaller table (let's say Customers) is sent to every worker node (executor) in the cluster. This means each executor gets a complete copy of the Customers table.
3. Building a hash table: On each executor, a hash table is built using the join key (e.g., customer ID) from the broadcasted table (Customers). This hash table acts like a dictionary, making it easy to find specific rows based on their key.
4. Probing the larger table: The larger table (Orders) is scanned row by row on each executor.
5. Matching using the hash table: For each row in the larger table, the join key is used to look up the corresponding row in the hash table (built from the broadcasted table).
6. Joining the rows: If a match is found in the hash table, the rows from both tables are joined based on the join condition and added to the final output.
7. Combining results: Finally, the results from each executor are combined to form the final joined table.
Advantages:
Faster Performance: BHJ can be significantly faster than other join strategies, especially for small datasets. This is because one dataset (typically the smaller one) is broadcasted entirely to all worker nodes (executors) in the cluster. This eliminates the need for shuffling data across the network, which can be a bottleneck in other join methods.
Reduced Network Traffic: By avoiding shuffling the larger dataset, BHJ consumes less network bandwidth, making it efficient in clusters with limited network resources.
Simplicity: BHJ is often considered a simpler join strategy to understand and implement compared to other options like Shuffle Hash Join or Sort Merge Join.
Disadvantages:
Limited Applicability: BHJ is only effective for small datasets. Broadcasting a large dataset to all executors can consume significant memory and network resources, making it impractical for larger datasets.
Memory Constraints: Each executor needs enough memory to hold the entire broadcasted dataset. If the dataset is too large or the executors lack sufficient memory, BHJ might not be feasible.
Overhead: Broadcasting itself incurs some overhead in terms of network and CPU resources, which can negate the performance benefit for very small datasets. BHJ might not be optimal for datasets close to the "too large" limit for broadcasting.
Manual Tuning: While Spark automatically chooses BHJ for small datasets by default, it might not be the optimal choice for borderline cases. You might need to manually adjust the size limit for broadcasting based on your cluster configuration.
Conditions to fulfill:
Join Type: Join being performed must be an equi join (i.e. ==).
Join Operation: Join operation should not be Full Outer.
Dataset Size: One table should be significantly smaller than the other, ideally by a factor of 10 or more.
'''Setup Config'''
spark.conf.set("spark.sql.join.autoBroadcastJoinThreshold", 10 * 1024 * 1024)
spark.conf.set("spark.sql.join.preferSortMergeJoin","false")
'''Check Config'''
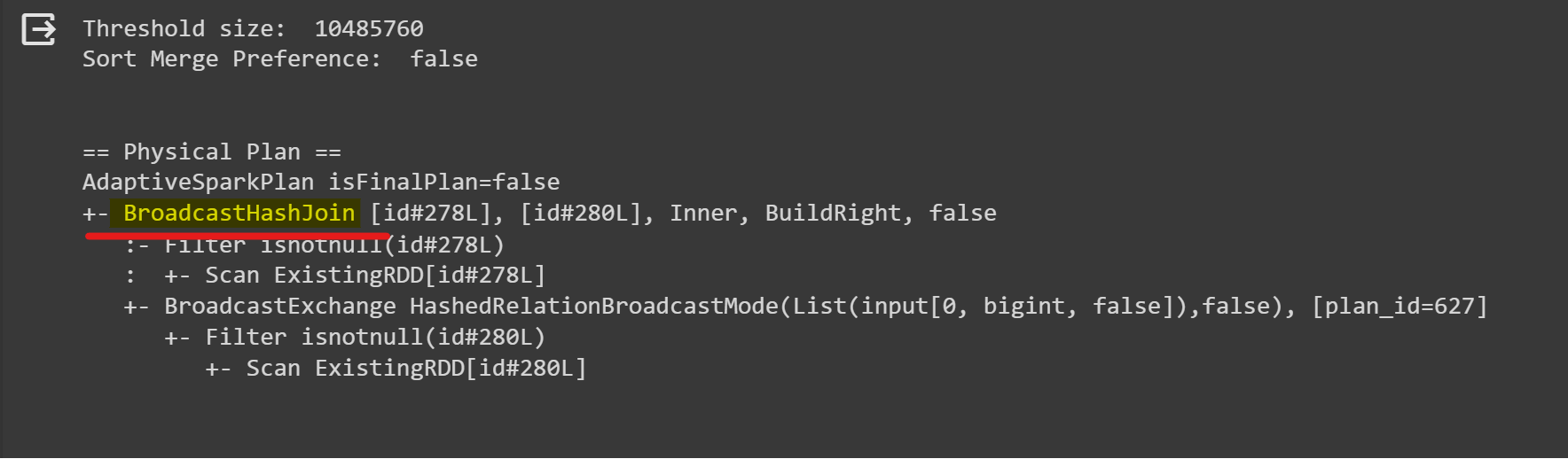
print("Threshold size: ",spark.conf.get("spark.sql.join.autoBroadcastJoinThreshold"))
print("Sort Merge Preference: ",spark.conf.get("spark.sql.join.preferSortMergeJoin"))
print(end="\n\n")
'''Create Schema'''
schema = ["id"]
'''Create Big DF'''
bigDF = spark.createDataFrame(data=[(x,) for x in range(1,21)], schema=schema)
# bigDF.show()
'''Create Small DF'''
smallDF = spark.createDataFrame(data=[(x,) for x in range(1,21,2)], schema=schema)
# smallDF.show()
'''Perform Join'''
joinedDF = bigDF.join(broadcast(smallDF), bigDF.id == smallDF.id, "left")
# joinedDF.show()
'''View execution plan'''
joinedDF.explain()
Output:
Shuffle Hash Join (SHJ)
Shuffle - Sort - Merge Join (SSMJ)
Cartesian Join (CPJ)
Broadcast Nested Loop Join (BNLJ)
References:
I've taken references from below people:
Jyoti Dhiman:Spark Join Strategies — How & What?
Aman Kumar Gupta:Join Strategies in Apache Spark — A hands-on approach!
The post is yet to be completed